
1. 주요 개념 정리
- Series : 1차원 데이터
- DataFrane : 2차원 데이터
- index(인덱스) : 행 순서, *각 행(row)를 식별하기 위한 고유한 키(Key) → *데이터에 접근할 수 있는 주소 값
- column(컬럼) : 세로줄, 같은 종류의 속성이 모여있는 집합 → 특정한 항목에 대한 모든 값이 들어 있는 데이터
- row(행) : 가로줄, 하나의 데이터 기록(레코드)의 집합
2. 데이터 실분석
- Data.co.kr 공공데이터포털에서 실데이터의 csv 파일을 불러올 수 있다.
- → 여기에서 얻은 csv 파일을 판다스 read_csv 함수를 통해 불러올 수 있다.
- 데이터 분석을 위한 계산을 위해 라이브러리 numpy를 사용하며, 이를 시각화 하기 위하여 matplot 뭐시기, seaborn을 사용함.
- https://www.boostcourse.org/ds112/lecture/59937?isDesc=false → 낯선 데이터를 파악 및 분석하고 어떤 흐름으로 데이터를 분석해나가는지 이해하는게 중요할듯
*
2.5 데이터 시각화 - pandas
아래 데이터는 전국 의료 관련 업체에 대한 데이터를 사용한다.
df["상권업종대분류명"].unique() ← 이 명령어를 통해 알 수 있다.
→ 결과 : array([’의료’], dtype=object)
( unique() → 중복값을 제거하고, 컬럼이 가지고 있는 속성값 종류를 리턴한다. )
- 막대형 리스트 → 각 컬럼의 속성 값이 서로 관련되어 있지 않은 경우, 값 끼리 비교가 필요한 경우 이와 같이 막대형 리스트를 이용하는게 나을거 같음.

- 파이 차트 → 아래는 파이 차트의 예이나, 서울과 경기도의 차이를 알기 힘들고, 각 도시의 차이를 알기가 쉽지 않기에 아래 데이터는 막대 그래프를 사용하는 것이 더 이점이 있겠다.
2.5 데이터 시각화 - seaborn, matpliotlib
seaborn의 장점 : 고급 통계 기능을 그래프 내부에서 제공한다.
seaborn의 단점 : 데이터 크기가 클수록 속도가 느리다.
- 실습 1. 위도, 경를 활용한 대한민국의 가게 분포와 시각화
- 데이터 크기 분석
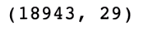
- ㄴ 18943개의 레코드(가게)가 있고 29개의 컬럼(구)가 있음.
df_seoul = df[df["시도명"] == "서울특별시"].copy() # df_seoul에 시도명이 서울특별시인 데이터를 복사후 집어넣음 df_seoul.shape # 구조 분석- 막대 그래프를 활용한 시군구 별 가게 분포도 분석
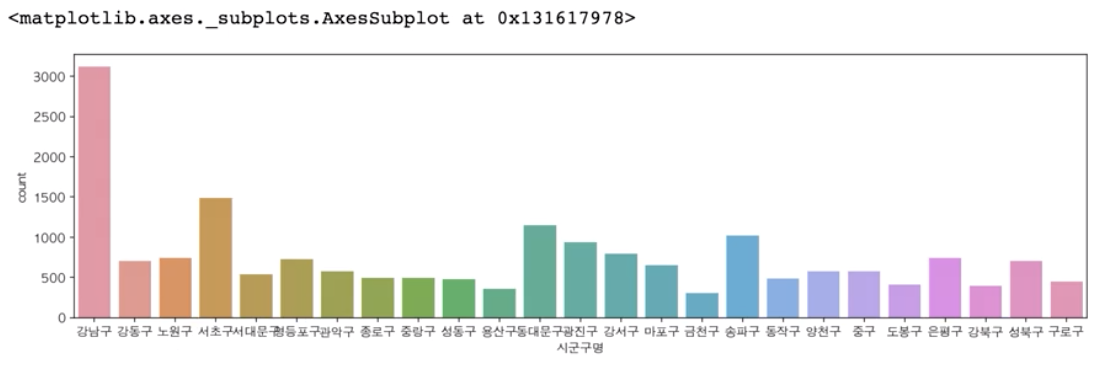
plt.figure(figsize=(15, 4)) sns.countplot(data=df_seoul, x="시군구명")
- 데이터 크기 분석
- 데이터에 있는 경도 위도 정보를 활용하여 scatter plot 형태의 그래프 구현
df_seoul[["경도", "위도", "시군구명"]].plot.scatter(x="경도", y="위도", figsize=(8, 7), grid=True) 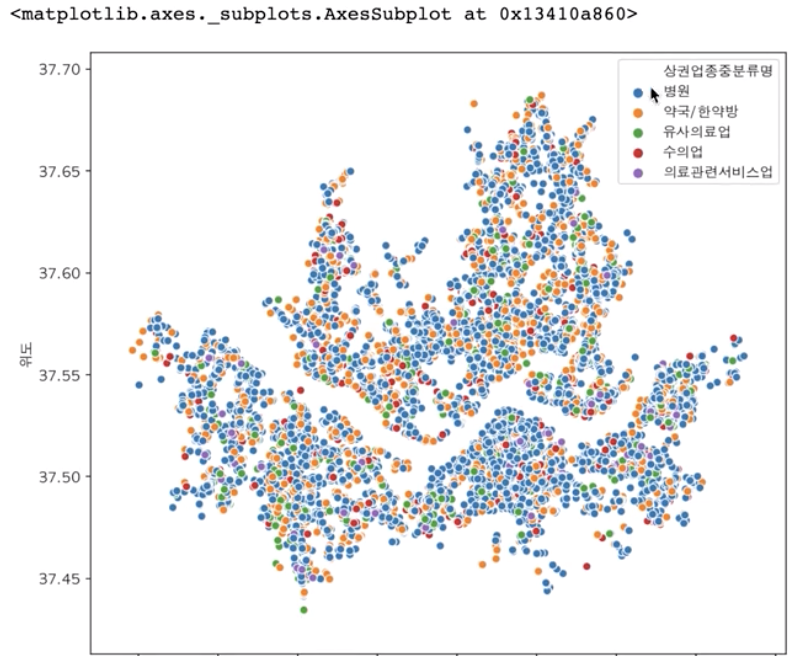
- seaborn의 hue 매개변수 활용하여 더욱 구체화
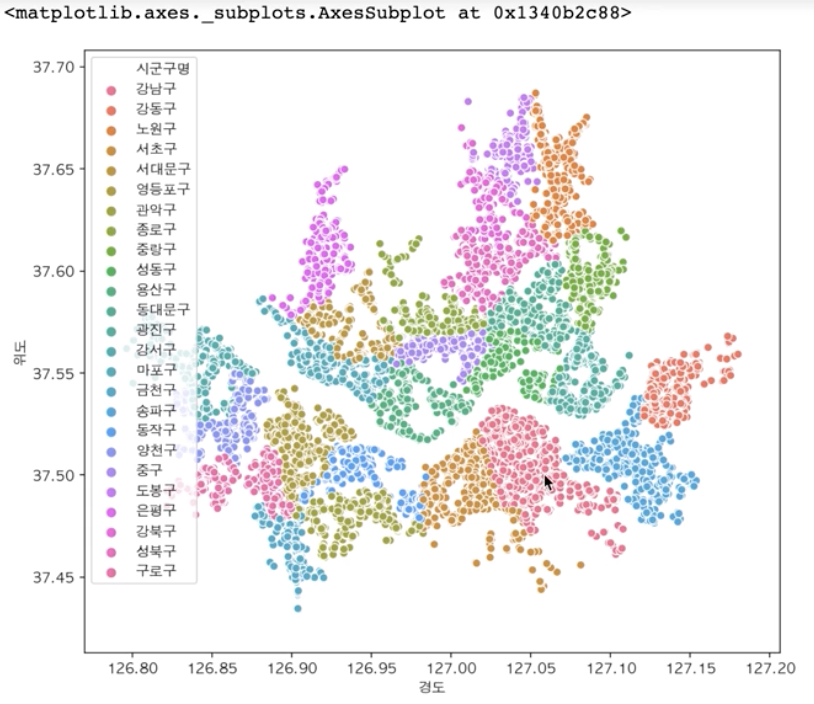
plt.figure(figsize=(9, 8)) sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="시군구명")plt.figure(figsize=(9, 8)) sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="상권업종중분류명")
데이터에서 얻고자하는 정보가 무엇인가에 따라서 막대그래프, scatter 그래프 등 사용할 그래프의 종류와 표시할 정보의 종류가 달라진다. 막대 그래프는 각 시도별 가게의 수를 한눈에 확인할 수 있고, scatter plot 그래프는 시도별 내에서도 어디에 가장 밀집되어 있는지 한눈에 확인할 수 있게 된다.
- 추가. 지리 데이터를 더욱 효율적으로 → 폴루므?

for n in df_seoul_hospital.index: name = df_seoul_hospital.loc[n, "상호명"] address = df_seoul_hospital.loc[n, "도로명주소"] popup = f"{name}-{address}" location = [df_seoul_hospital.loc[n, "위도"], df_seoul_hospital.loc[n, "경도"]] folium.Marker( location = location, popup = popup, ).add_to(map) map
이 라이브러리를 활용하면 기존에는 단순 좌표평면에서 지도가 보였지만 위 사진 처럼 뒤에 배경으로 실제 지도를 기반으로 시각화가 가능하다. 위 그래프를 보니 서울 외각으로 갈수록 종합병원이 줄어들고 있다는 것을 알 수 있었다.- 실습 2. 건강검진 정보를 활용하여 가설 검정하기두번째, 신장 또는 허리둘레의 크기가 체중이랑 상관관계가 있을까?
- 결측치 분석 및 변경 → 데이터 분석할때 무조건 해야하는 과정인듯
- A. 결측치의 데이터 프레임 출력
- 위 가설을 검증하기 위하여 아래와 같은 과정을 거치겟다.
첫번째, 음주 여부는 건강검진 수치와 차이가 있을까?
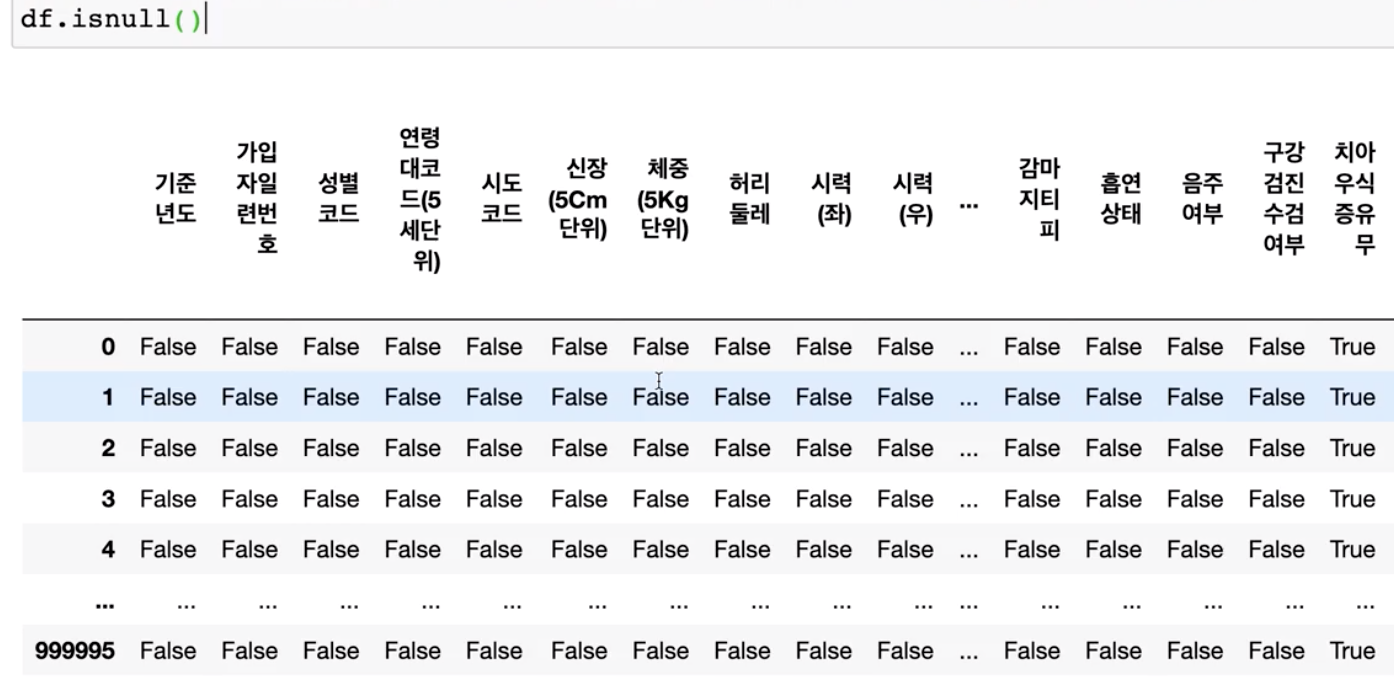
→ 어떠한 컬럼에 결측치가 얼마나 존재하는지를 분석하기 위하여 결측치를 출력했으나 데이터가 너무 많은 관계로 치아 증식 유무 외 결측치를 분석하기가 어려움 → **시각화를 해야한다.**
B. 막대그래프를 활용한 시각화 
→ 위 그래프를 통해 꽤 많은 컬럼에 결측값이 있다는 것을 알 수 있다. 하지만 특정 컬럼의 결측값 개수가 너무 많은 탓에 요단백, LDL 콜레스테롤과 같은 수치를 놓칠수도 있겠다. 만약 결측값이 단 한개라면 거의 보이지도 않을것이다.
A. 각 컬럼의 결측치 값이 True 인것을 sum 해서 dataframe으로 시각화
→ 이제 잘보인다. 이제보니 43개와 같이 아주 적은 갯수의 결측치를 가지고 잇는 컬럼도 있었다. 만약 막대그래프로만 결측치를 분석했다면 놓쳤을수도 있다. → 값끼리의 차이가 매우 큰 데이터는 막대그래프가 적합하지 않다는 것을 알 수 있다.
2. 이상치 점검
이상치 : 비정상적으로 작거나, 큰 값 → **이상치로 인해 평균과 같은 통계 연산에 왜곡을 줄 수 있음**
A. 디스크립션 뭐시기 함수를 통해 각종 통계 값 확인하기
→ 75% 까지의 값은 많아봤자 63인데, 최대값이 999임에 따라 통계에서 왜곡이이 발생하고 있음을 알 수 있다. '개발 관련 개념' 카테고리의 다른 글
| 손실함수의 의미 및 대표적 손실함수 (MAE, MSE) (0) | 2025.11.26 |
|---|